Research data management is an integral part of modern science that ensures research quality, integrity, and sustainability. It involves a systematic approach to planning, organizing, storing, documenting, and sharing data throughout the entire research project lifecycle.
Effective data management not only facilitates the research process itself but also increases the reliability of results, ensures compliance with international standards and funder requirements, and promotes scientific collaboration. The FAIR principles – data findability, accessibility, interoperability, and reusability – have become the foundation of modern research data management.
Here you will find the fundamental concepts and principles necessary to understand the nature of research data, their types and lifecycle, as well as the importance of FAIR principles in quality scientific work.
Research data is any information collected, observed, or created during a research project and used as the basis for obtaining research results and drawing conclusions. There is enormous data diversity, and data can exist in various forms and formats:
- Primary data (collected by the researcher):
- experimental results – laboratory measurements, chemical analysis data, physical tests
- interview recordings – audio/video materials, transcriptions, field notes
- survey data – questionnaire responses, statistical data, demographic indicators
- software code – data processing scripts, algorithms, program source code
- visual materials – photos, videos, scans, microscopy images
- measurement tables – sensor data, observation protocols, calibration data
- sample data – biological samples, geological materials, archaeological finds
- Secondary data (obtained from other sources):
- statistical data
- archival materials
- open data from data portals and research repositories
- scientific databases – bibliographic records, publication catalogues, patent registers
A dataset is a collection of similar or related research data grouped for research purposes.
Research data management is a process in which information or data obtained during research is systematically planned, organized, stored, shared, and preserved. The goal of research data management is to ensure that data is secure, reusable, transparent, and compliant with both ethical and legal requirements.
Research data management is closely linked to the research project process, and both processes have mutually complementary lifecycles. As shown in the diagram, the data management and research lifecycle include several interconnected stages, from planning to sharing/publishing.
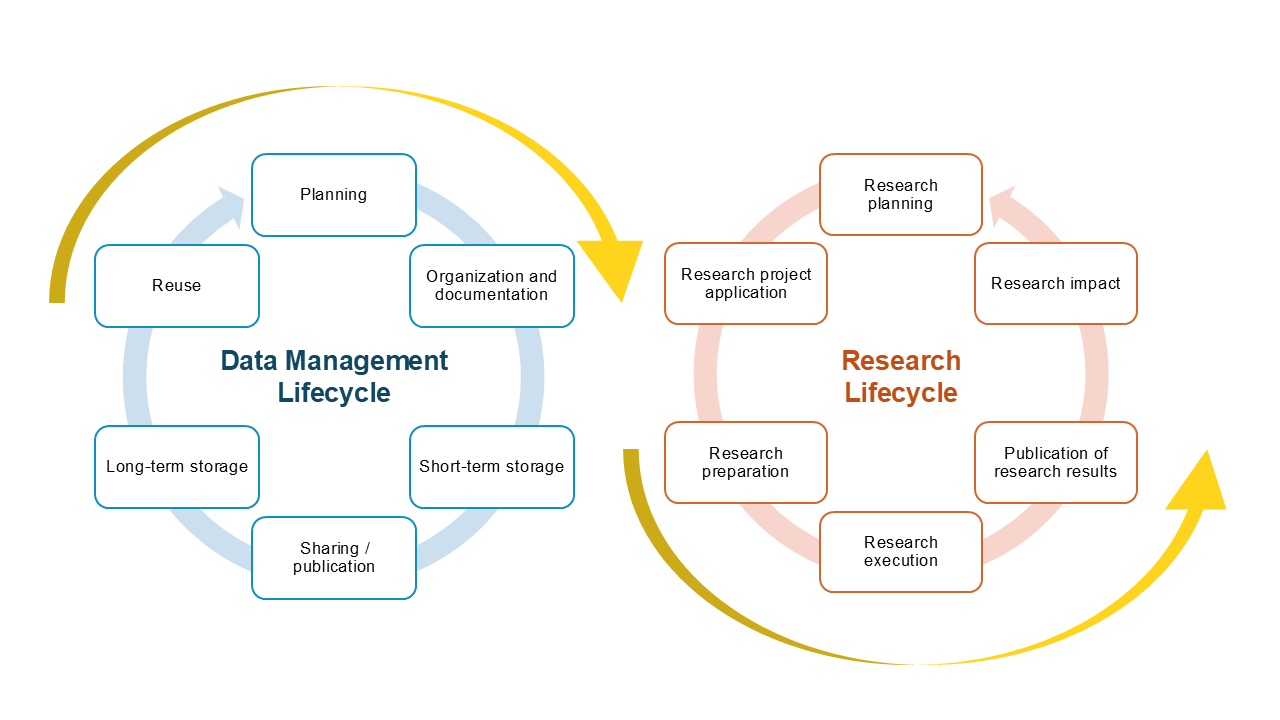
Research data management is closely linked to the research project process, and both processes have mutually complementary lifecycles. As shown in the diagram, the data management and research lifecycle include several interconnected stages, from planning to sharing/publishing.
During the research planning stage, research objectives are defined, methodology is selected, and data management needs are identified. In the research preparation phase, specific instruments are developed, necessary technical solutions are prepared, data collection procedures are organized, and a detailed data management plan with necessary data management activities is prepared.
During the research execution phase, active data collection, preprocessing, and quality control take place, while simultaneously ensuring secure storage and systematic organization. This phase also includes the data processing and analysis stage, where data is transformed, analysed, and interpreted, while creating necessary documentation and metadata.
In the research completion phase, results are published, but data is evaluated in the context of its future value – some is prepared for publication and long-term archiving, while others may be deleted if their preservation is not necessary.
Effective research data management requires appropriate planning and implementation for each stage, considering both project-specific and data-specific needs. Therefore, it is not possible to develop one universal data management model that would be suitable for all studies.
FAIR principles are guidelines that define what research data should be:
- findable – data and its metadata are easily discoverable by other researchers and systems
- accessible – data is available, and access conditions are clearly specified
- interoperable – data is compatible with other systems and datasets
- reusable – data is prepared so that it can be reused in the future
The FAIR principles emphasize machine-readability (i.e., the ability of computational systems to find, access, interoperate, and reuse data with minimal or no human intervention). Due to the increasing volume, complexity, and speed of data creation, there is growing reliance on computational support for data processing, making the implementation of FAIR principles increasingly important.