Research data publishing is an essential step in implementing open science. By publishing their data, researchers promote transparency, reproducibility, and contribute to broader knowledge circulation.
Nowadays, data publishing is becoming standard practice, increasingly required by funders and scientific journals. It is not only an ethical responsibility to the scientific community but also a practical necessity to ensure research quality and trustworthiness.
Effective data publishing includes choosing an appropriate repository, proper licensing, preparing quality metadata, and observing sensitive data protection measures. Properly published data becomes a significant scientific resource that serves not only the researchers themselves but also the broader scientific community.
DataverseLV – primary choice
Deposit research data and/or metadata in the DataverseLV data repository. DataverseLV provides quality control – data stewards review each deposited dataset, evaluating metadata completeness and data structure. Only after review do data stewards publish the datasets. Such control ensures that published data complies with FAIR principles and is suitable for reuse.
Alternative repositories
If necessary, data can be published in another appropriate research data repository. Important: If data is published in another research data repository, the DMP must include justification for the repository choice!
When other repositories can be used:
- field-specific requirements – a specialized repository exists in the field (for example, GenBank for biology, ICPSR for social sciences)
- funder requirements – project contract requires using a specific repository
- international collaboration – partners use another repository (for example, Zenodo, Figshare, Dryad)
- special data formats – repository supports specific data types
Mandatory criteria for choosing other repositories:
- FAIR principles compliance – repository ensures that data is findable (with search functions), accessible (with clear access conditions), interoperable (compatible with other systems), and reusable (with complete metadata)
- long-term preservation (at least 10 years) – repository guarantees secure data storage and long-term availability, even if technologies or organizations change
- persistent identifier assignment – repository automatically assigns DOI (Digital Object Identifier) or other persistent identifier (PID), allowing reliable citation of data in scientific publications and providing stable reference even if data is moved
Data in repositories can be published at different accessibility levels, allowing researchers to choose the most appropriate solution depending on data nature, sensitivity, and legal requirements:
- open data – freely available to anyone without restrictions. Can be immediately downloaded, used, and distributed free of charge, observing specified license conditions. This is the most desirable option in the open science context.
- restricted access data – available under special conditions, for example, by registering or requesting access permission from the dataset owner. This approach is suitable when control over data use is necessary.
- closed data – not in public use and available only to a limited circle of people. However, a metadata record about closed data can be created in the repository to inform other researchers that such a dataset exists.
- embargo periods – sometimes researchers choose to set an embargo period, meaning that for a certain period data is not publicly available, but will be opened in the future. Such restriction may be related to copyright, intellectual property protection, or publication requirements. Embargo periods should not exceed 1-2 years after project completion.
A licence is a legal document that determines how others may use, share, modify, or distribute published data. Without a licence, others lack legal clarity about whether and how data may be used – this can stop data use and reduce its scientific value. An appropriate licence provides both author rights protection and clear rules for other researchers.
Creative Commons (CC) licences:
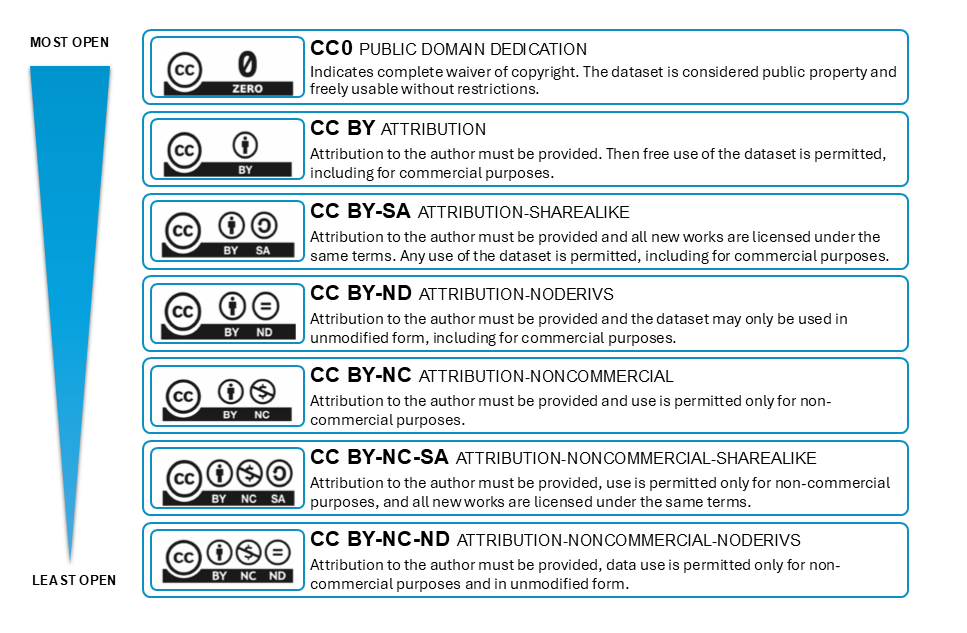
Licence selection
Choose a licence based on data nature, sensitivity, and desire to control its use. The more open the licence, the easier it is to use and cite data. To help determine the most appropriate licence type for research results, you can use an online licence selection tool.
Sensitive data is not suitable for direct publication. If it's necessary to make data available to the broader scientific community, anonymization can be used (data deletion, generalization, microaggregation, or shuffling methods), reduced data versions can be created with decreased detail that doesn't contain identifying information, or only metadata with information about data existence and access possibilities can be published in the repository.
This approach allows observing open science principles while protecting confidentiality and complying with legal requirements. It ensures balance between scientists' need for data availability and research participants' privacy protection, while maintaining research reproducibility.
For data to be a full-fledged scientific resource, it must be citable just like publications. When publishing data in a trusted repository, it is assigned a persistent identifier (usually DOI), which allows convenient citation.
| Standard data citation format: Author(s) (year). Dataset title. Repository name. DOI |
Example: Boča Antra; Cornu Sophie; Saby Nicolas P.A. (2025). Spatial Dataset of Modified FAO Soil Unit Proportions and Climate Variables for Modelling Climate-Driven Zonal Soil Distribution. DataverseLV, https://doi.org/10.71782/DATA/UELKUT, v1 |
Recommendations for data citation:
- specify authors (or institution), title, publication year, repository, DOI or another identifier
- if possible, also mention data version (for example, v1.2), as data may change
- data citation is often required by funders and journals – include them also in the publication reference list
Increasingly, international scientific journals include a data availability statement as a separate section of scientific articles. This statement indicates whether and how research data is available to other researchers.
Examples in data availability statements:
| Publicly available data | "All data used in the study are publicly available and can be found in the DataverseLV repository with the following DOI: ..." |
| Data upon request | "Data available upon request by contacting the corresponding author of the scientific article." |
| Restricted data | "The dataset contains sensitive information and is not publicly available. Metadata and data description are available in the DataverseLV repository." |
- Use the DataverseLV data repository as the first choice
- Document alternatives – if using another repository, justify the choice in the DMP
- Publish datasets as quickly as possible and follow the principle "as open as possible, as restricted as necessary"
- Prepare quality metadata – rich description improves data findability and usability
- Use standard formats – .csv, .xml, .tiff and other open formats ensure long-term availability
- Add a ReadMe file – detailed description will help others understand and use data
- Consult with data stewards – write to datu.kuratori@lu.lv about any research data management questions